Rでggplot2を使ってロジスティック回帰分析の結果のオッズをフォレストプロット風のプロット図を作成する
(追記)
オッズ比と95%信頼区間を{broom}パッケージのtidy()使って計算する方法を書いた(あまり大差ない)。
(追記終了)
Rでロジスティック回帰分析をしてオッズ比を出して、そのオッズ比をggplot2でフォレストプロット風のプロット図(95%信頼区間エラーバー付き)を作る。
最終的にできる成果物は
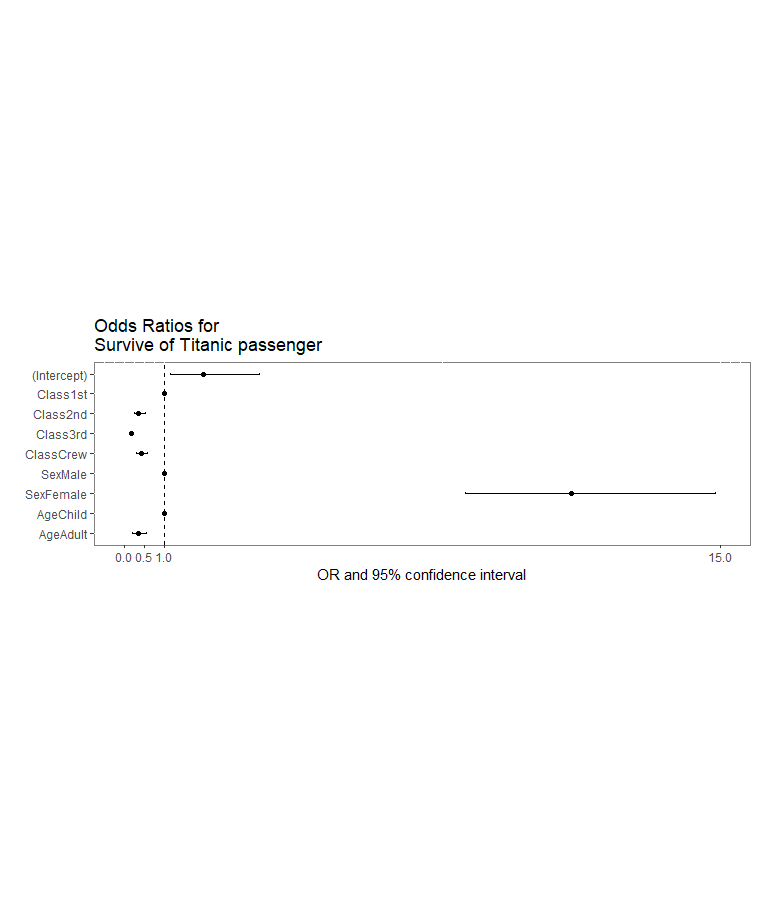
使うデータはオッズ比と95%信頼区間の上限値と下限値なので、ハザード比でも同じ手法で描けるはず。
「こういう図描きたいけど、どういう感じなんだ? パッケージないのかな」と思いながら調べてみても何図(何プロット)か当て所なく調べたため良いパッケージ見つからず、ggplotをいじりながらようやっとイメージ通りのものがかけえそうになってから「フォレストプロット!?」となったので、{metafor}や{foerstplot}で簡単に描けそうではある。
負け惜しみとしてはメタアナリシス用のフォレストプロットのようにサンプルサイズがわかる必要もないし、ggplotなので図として今後も入れたいものがあればガシガシ重ねていけるし、サイズ調整も割と自由が効くという拡張性があるはず。
とりあえずRの組み込みデータのタイタニック号乗船者の生存データをつかってやってみる。
Titanicデータの中身はClass(等級)、Sex(性別)、Age(大人か子供か)、Survive(生死)になっている
Titanic , , Age = Child, Survived = No Sex Class Male Female 1st 0 0 2nd 0 0 3rd 35 17 Crew 0 0 , , Age = Adult, Survived = No Sex Class Male Female 1st 118 4 2nd 154 13 3rd 387 89 Crew 670 3 , , Age = Child, Survived = Yes Sex Class Male Female 1st 5 1 2nd 11 13 3rd 13 14 Crew 0 0 , , Age = Adult, Survived = Yes Sex Class Male Female 1st 57 140 2nd 14 80 3rd 75 76 Crew 192 20
とクロス表の集まりになっているので、このままだと使いにくいのでデータフレーム化してFreqでそれぞれの属性を持つ人での数がわかるので、もとの一人1行になるように前処理する(教科書とかによるある手順)。
# タイタニックのデータをデータテーブルにする d <- data.frame(Titanic) d.data <- data.frame( Class = rep(d$Class, d$Freq), Sex = rep(d$Sex, d$Freq), Age = rep(d$Age, d$Freq), Survived = rep(d$Survived, d$Freq) )
すると
head(d.data) Class Sex Age Survived 1 3rd Male Child No 2 3rd Male Child No 3 3rd Male Child No 4 3rd Male Child No 5 3rd Male Child No 6 3rd Male Child No
となるので、これをロジスティック回帰分析していく
# 生存のロジスティック回帰分析、一応中身を見ておく d.logit <- glm(Survived~., data = d.data, family = binomial(link = "logit")) summary(d.logit) Call: glm(formula = Survived ~ ., family = binomial(link = "logit"), data = d.data) Deviance Residuals: Min 1Q Median 3Q Max -2.0812 -0.7149 -0.6656 0.6858 2.1278 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 0.6853 0.2730 2.510 0.0121 * Class2nd -1.0181 0.1960 -5.194 2.05e-07 *** Class3rd -1.7778 0.1716 -10.362 < 2e-16 *** ClassCrew -0.8577 0.1573 -5.451 5.00e-08 *** SexFemale 2.4201 0.1404 17.236 < 2e-16 *** AgeAdult -1.0615 0.2440 -4.350 1.36e-05 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 (Dispersion parameter for binomial family taken to be 1) Null deviance: 2769.5 on 2200 degrees of freedom Residual deviance: 2210.1 on 2195 degrees of freedom AIC: 2222.1 Number of Fisher Scoring iterations: 4
ここからが本題。
オッズ比と95%信頼区間を求めてオブジェクトに保存して、ggplot2で使えるようにデータフレーム化しておく
# オッズ比と95%信頼区間を計算しデータフレーム化する d.conf <- exp(cbind(OR = coef(d.logit), confint(d.logit))) d.conf <- data.frame(d.conf) # d.confの中身を見ておく head(d.conf) OR X2.5.. X97.5.. (Intercept) 1.9844057 1.1611867 3.3899109 Class2nd 0.3612825 0.2453064 0.5291859 Class3rd 0.1690159 0.1203213 0.2358425 ClassCrew 0.4241466 0.3115232 0.5774746 SexFemale 11.2465380 8.5727281 14.8700792 AgeAdult 0.3459219 0.2140861 0.5578928
で、オッズ比と95%信頼区間のデータフレームができた。
d.confだけを流し込むと順番がオッズ比でソートされてしまうのでそれを避けるために、y軸側の順番を先に規定する。
# 順番用のベクトルを作る、行数の空ベクトル y_order <- length(nrow(d.conf)) # ループ処理しながら行名を下から順番に取り出す x <- 1 for(i in nrow(d.conf):1){ y_order[x] <- row.names(d.conf)[i] x <- x +1 }
y軸rreverseでも良さそうだが、d.confデータフレームをオッズ比と信頼区間以外で汚したくないので適当な数字を他に入れない関係で使えない。
名前をy軸に直接設定するときに名前を図の下になる方から順番に取り出す必要がある。
毎回手書きをするのが嫌なので、項目数は100項目とかにはならないはずなので、次もちょっと書き換えるだけで使えるループ処理で取り出す。
これをggplot2でプロット&エラーバーをつけるには表の範囲で97.5%で一番大きい値を天井関数に入れてやって設定しようとしているので{ggplot2}だけじゃなく{dplyr}も使う。
library(ggplot2) library(dplyr) # ggplotでフォレストプロット風オッズ比の95%信頼区間付きをプロットする ggplot(d.conf, aes(OR,row.names(d.conf)))+ # プロット geom_point()+ # x軸1で破線を引く geom_vline(xintercept = 1, linetype = "dashed")+ # 背景をグレーから白にする theme(panel.background = element_rect(fill = "white", color = "grey50"))+ # 軸ラベルとタイトルを付ける labs(title = "Odds Ratios for\nSurvive of Titanic passenger", x = "OR and 95% confidence interval", y = "")+ # 95%信頼区間をエラーバーで描く、バーの端がでかいのでwidthで小さくする geom_errorbar(aes(xmin = X2.5.., xmax = X97.5..), width = 0.1)+ # 項目をロジスティック回帰分析の式の順番になるように並べ直す scale_y_discrete(limits = y_order)+ # 表の大きさ調整、横長なら数字を大きく、縦長なら1より小さい分数で coord_fixed(ratio = 1/2 )+ # x軸の表現を変更、右端は95%信頼区間の最大値の天井関数になるよう計算 scale_x_continuous(limits = c(0,ceiling(summarise(na.omit(d.conf), max(X97.5..))[,1])), breaks = c(0,0.5,1, ceiling(summarise(na.omit(d.conf), max(X97.5..)))[,1]))

となる。
ggplot2の中身でこの処理だけだといらない処理もいくつかある。
例えばna.omit()は今回の処理だけで終わるならいらない。
VS男とか、VS子供を別で記載するとかならこれで終わってもこの図だけでもわかると思う。
VSをどこかに書くのがめんどくさいので、図の中にオッズ比1の項目を入れることで暗にこれとVSだよとわかるようにしたい。
ここからかなり泥臭く、項目名を入力したり、順番を行番号確認しながら手入力で入れ替えていく必要がある。
もう少し良い手法があればいいのだけれど……
1stクラス、男性、子供のオッズ比1、信頼区間なしのものをd.confに入れて、それぞれのVS対象の上に来るようにする。
# 比較のためのオッズ比1信頼区間なしの行を作る d.conf[7,] <- c(1,NA,NA) d.conf[8,] <- c(1,NA,NA) d.conf[9,] <- c(1,NA,NA) row.names(d.conf)[7:9] <- c("Class1st", "SexMale", "AgeChild") d.conf <- d.conf[c(1,7,2,3,4,8,5,9,6),]
このうえで、y軸の順番を規定するためのオブジェクトを作るところからやり直すと、fig.1が描出できる。
na.omitはsummarizeしたときにNAデータがあるとNAを返してしまうので、それを回避するために必要。
あとは、x軸の刻みを増やしたかったり、凡例を書いたりしていくといい感じの図になると思う。
こうやって描出されると属性の傾向が数字以上にわかりやすくなる……かもしれない。