R本体のRのパッケージの引用情報を参照する時に使うcitation()の役に立つかもしれないTIPS的なのものをまとめていく。だいたいヘルプドキュメントに書いてある。
引用情報を呼び出す
Rの本体の引用情報を一番簡単に取り出すには次のようにするとできる。
citation()
## To cite R in publications use:
##
## R Core Team (2023). _R: A Language and Environment for Statistical
## Computing_. R Foundation for Statistical Computing, Vienna, Austria.
## <https://www.R-project.org/>.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Manual{,
## title = {R: A Language and Environment for Statistical Computing},
## author = {{R Core Team}},
## organization = {R Foundation for Statistical Computing},
## address = {Vienna, Austria},
## year = {2023},
## url = {https://www.R-project.org/},
## }
##
## We have invested a lot of time and effort in creating R, please cite it
## when using it for data analysis. See also 'citation("pkgname")' for
## citing R packages.
これは既定値でcitation(package = "base")が実行されるため。
パッケージの引用情報を呼び出す場合は、パッケージ名を入力する。例えば{ggplot2}パッケージの場合は次のようにする。
citation("ggplot2")
## To cite ggplot2 in publications, please use
##
## H. Wickham. ggplot2: Elegant Graphics for Data Analysis.
## Springer-Verlag New York, 2016.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Book{,
## author = {Hadley Wickham},
## title = {ggplot2: Elegant Graphics for Data Analysis},
## publisher = {Springer-Verlag New York},
## year = {2016},
## isbn = {978-3-319-24277-4},
## url = {https://ggplot2.tidyverse.org},
## }
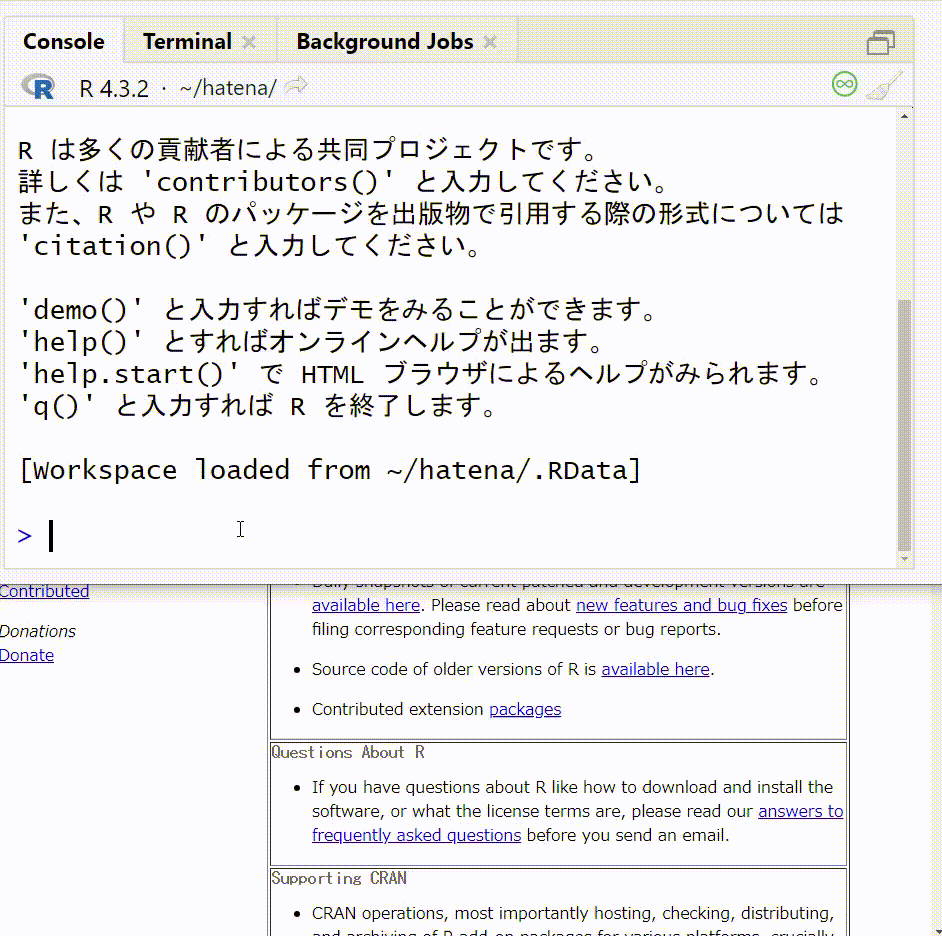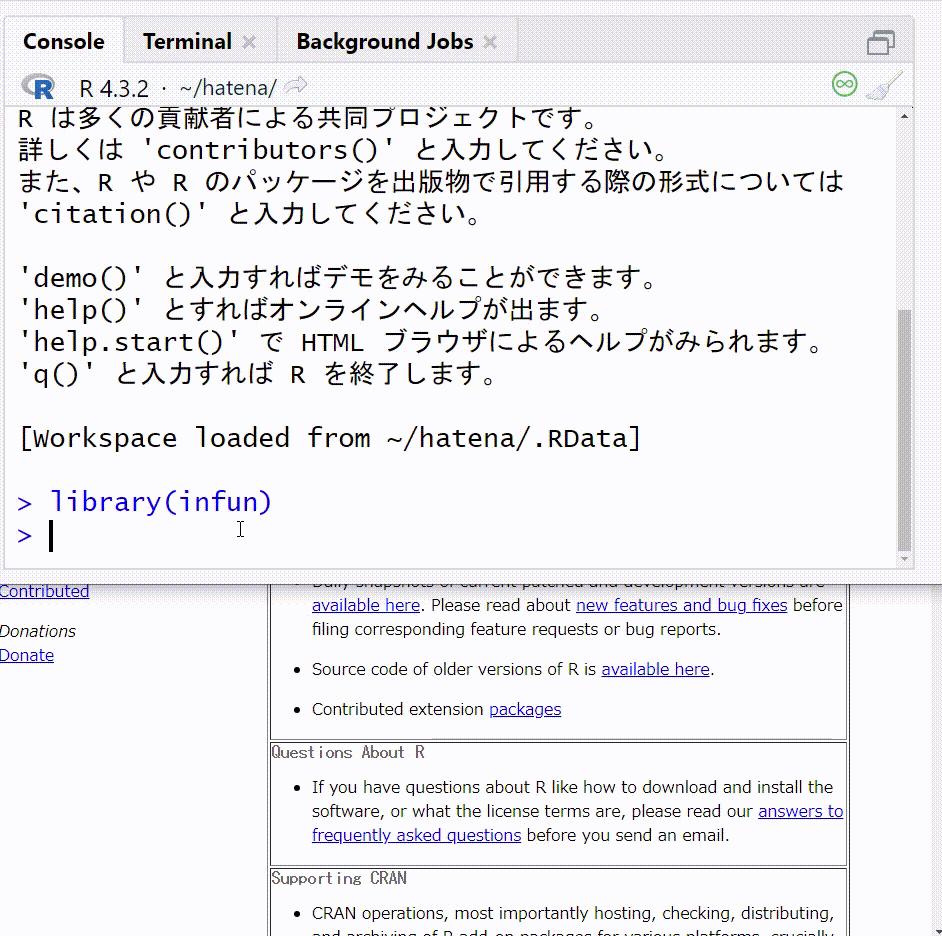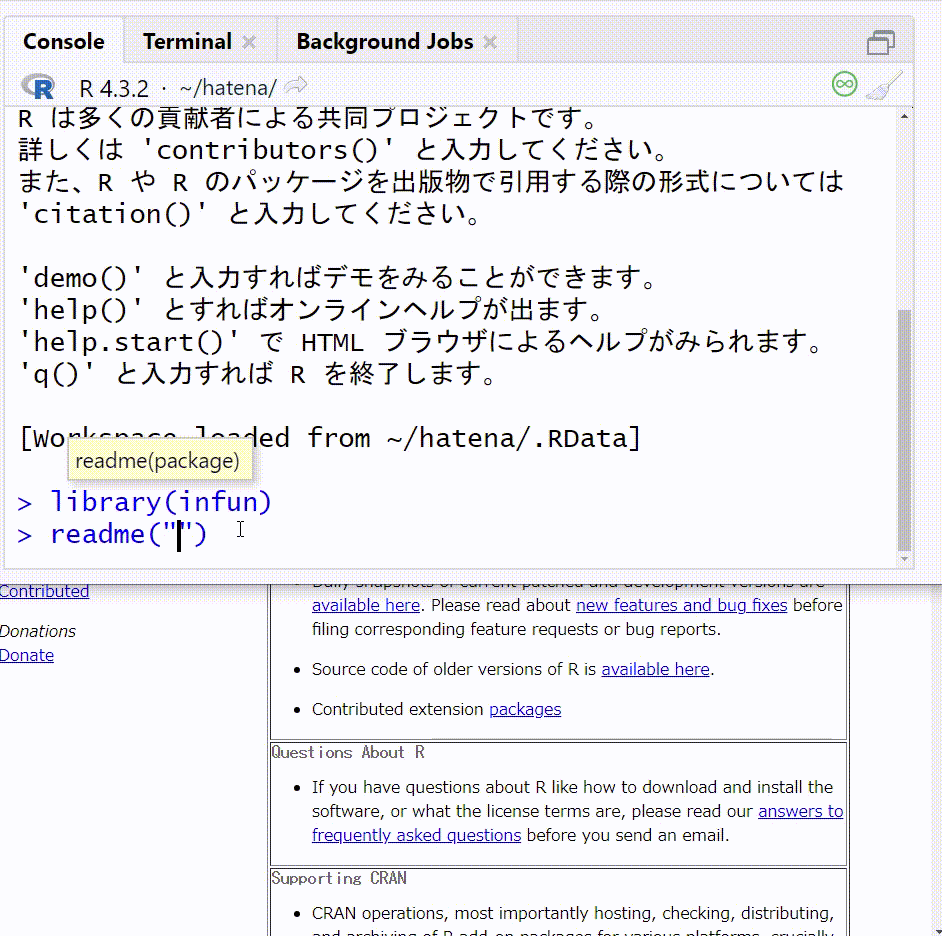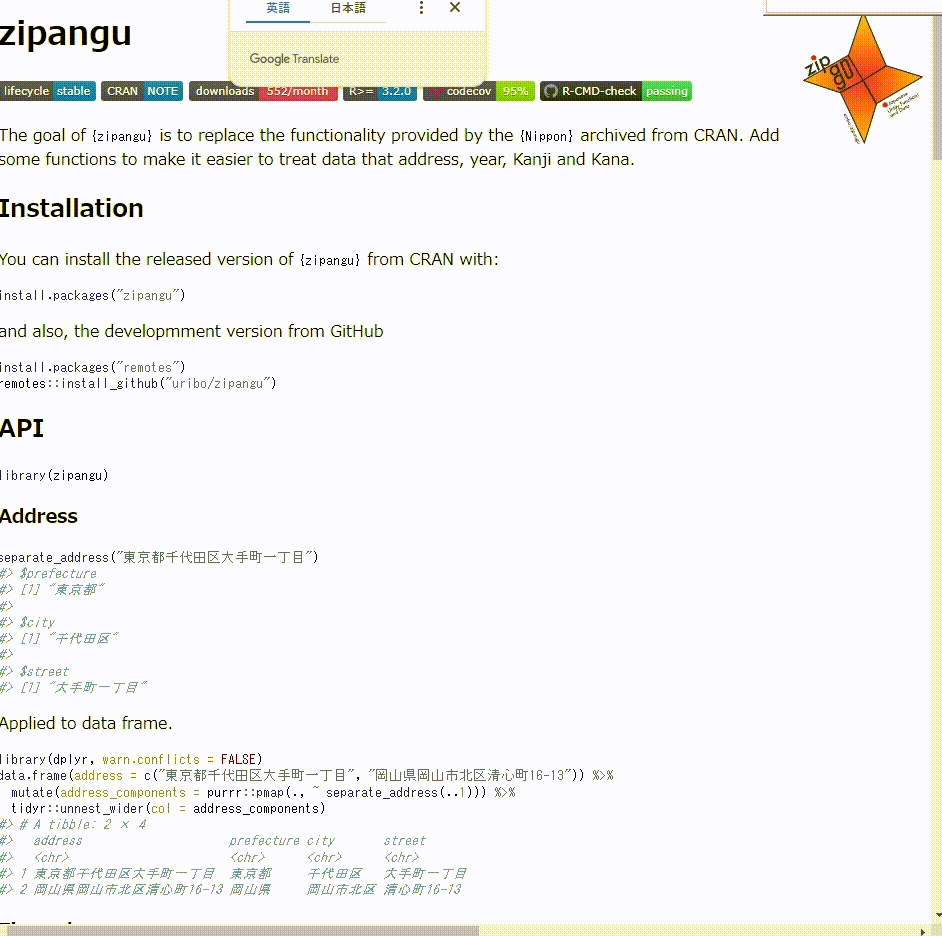
このとき、パッケージ内にCITATIONファイルがある場合には上記のようにCITATIONファイルの情報が呼び出させる({ggplot2}パッケージはCITAITONファイルがある)。CITATIONファイルがない場合はDESCRIPTIONファイルから所定の情報が呼び出される。例えば、CITATIONファイルのないパッケージの例として{zipangu}パッケージの例は次のとおりになる。
citation("zipangu")
## 'zipangu' パッケージの引用には以下を用いてください:
##
## Uryu S (2022). _zipangu: Japanese Utility Functions and Data_. R
## package version 0.3.2, <https://CRAN.R-project.org/package=zipangu>.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Manual{,
## title = {zipangu: Japanese Utility Functions and Data},
## author = {Shinya Uryu},
## year = {2022},
## note = {R package version 0.3.2},
## url = {https://CRAN.R-project.org/package=zipangu},
## }
ここで、CITAITONファイルがあるが、DESCRIPTIONファイルから呼び出した情報の引用情報がほしい場合(例えばバージョン情報などが必要な場合)には、auto = TRUEとするとDESCRIPTIONファイルの内容からの情報が出力される。
citation("ggplot2", auto = TRUE)
## 'ggplot2' パッケージの引用には以下を用いてください:
##
## Wickham H, Chang W, Henry L, Pedersen T, Takahashi K, Wilke C, Woo K,
## Yutani H, Dunnington D (2023). _ggplot2: Create Elegant Data
## Visualisations Using the Grammar of Graphics_. R package version
## 3.4.4, <https://CRAN.R-project.org/package=ggplot2>.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Manual{,
## title = {ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics},
## author = {Hadley Wickham and Winston Chang and Lionel Henry and Thomas Lin Pedersen and Kohske Takahashi and Claus Wilke and Kara Woo and Hiroaki Yutani and Dewey Dunnington},
## year = {2023},
## note = {R package version 3.4.4},
## url = {https://CRAN.R-project.org/package=ggplot2},
## }
なお、参照できる引用情報はインストールされているパッケージに限る。インストールしていないパッケージの引用情報はcitation()関数では参照できない。
citation("MISS")
## Error in citation("MISS"): 'MISS' という名前のパッケージはありません
ちなみに、CITATIONファイルがパッケージにあるかどうかは、system.file()で簡単にわかる。
system.file("CITATION", package = "ggplot2")
## [1] "C:/Users/User_name/AppData/Local/R/win-library/4.3/ggplot2/CITATION"
system.file("CITATION", package = "zipangu")
## [1] ""
引用情報の表示スタイルを調整する
citation()関数のヘルプドキュメントには詳細な記載はないが、bibenty()関数のヘルプドキュメントに記載がある通り、print()関数またはformat()関数のstyle引数を指定することで表示するスタイルを調整することができる。表示できるバリエーションはtext,
Bibtex, citation, html, latex, textVersion, Rとなっている。
それぞれ、{ggplot2}パッケージ(規定値でCITAITONファイルを読み込んだ場合)のprint()関数での表示は次のとおりとなっている。
ggplot2_citation <- citation("ggplot2")
print(ggplot2_citation, style = "text")
## Wickham H (2016). _ggplot2: Elegant Graphics for Data Analysis_.
## Springer-Verlag New York. ISBN 978-3-319-24277-4,
## <https://ggplot2.tidyverse.org>.
print(ggplot2_citation, style = "Bibtex")
## @Book{,
## author = {Hadley Wickham},
## title = {ggplot2: Elegant Graphics for Data Analysis},
## publisher = {Springer-Verlag New York},
## year = {2016},
## isbn = {978-3-319-24277-4},
## url = {https://ggplot2.tidyverse.org},
## }
print(ggplot2_citation, style = "citation")
## To cite ggplot2 in publications, please use
##
## H. Wickham. ggplot2: Elegant Graphics for Data Analysis.
## Springer-Verlag New York, 2016.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Book{,
## author = {Hadley Wickham},
## title = {ggplot2: Elegant Graphics for Data Analysis},
## publisher = {Springer-Verlag New York},
## year = {2016},
## isbn = {978-3-319-24277-4},
## url = {https://ggplot2.tidyverse.org},
## }
print(ggplot2_citation, style = "html")
## <p>Wickham H (2016).
## <em>ggplot2: Elegant Graphics for Data Analysis</em>.
## Springer-Verlag New York.
## ISBN 978-3-319-24277-4, <a href="https://ggplot2.tidyverse.org">https://ggplot2.tidyverse.org</a>.
## </p>
print(ggplot2_citation, style = "latex")
## Wickham H (2016).
## \emph{ggplot2: Elegant Graphics for Data Analysis}.
## Springer-Verlag New York.
## ISBN 978-3-319-24277-4, \url{https://ggplot2.tidyverse.org}.
print(ggplot2_citation, style = "textVersion")
## H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016.
print(ggplot2_citation, style = "R")
## bibentry(bibtype = "Book",
## textVersion = "H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016.",
## header = "To cite ggplot2 in publications, please use",
## author = person(given = "Hadley",
## family = "Wickham"),
## title = "ggplot2: Elegant Graphics for Data Analysis",
## publisher = "Springer-Verlag New York",
## year = "2016",
## isbn = "978-3-319-24277-4",
## url = "https://ggplot2.tidyverse.org")
citation()で作られるオブジェクトは既定値ではstyle = "citation"で実行されている。使いたい表示形式のものを指定して表示すればば良い。
format()関数の場合は次のようになる。
format(ggplot2_citation, style = "text")
## [1] "Wickham H (2016). _ggplot2: Elegant Graphics for Data Analysis_.\nSpringer-Verlag New York. ISBN 978-3-319-24277-4,\n<https://ggplot2.tidyverse.org>."
format(ggplot2_citation, style = "Bibtex")
## [1] "@Book{,\n author = {Hadley Wickham},\n title = {ggplot2: Elegant Graphics for Data Analysis},\n publisher = {Springer-Verlag New York},\n year = {2016},\n isbn = {978-3-319-24277-4},\n url = {https://ggplot2.tidyverse.org},\n}"
format(ggplot2_citation, style = "citation")
## [1] ""
## [2] "To cite ggplot2 in publications, please use\n\n H. Wickham. ggplot2: Elegant Graphics for Data Analysis.\n Springer-Verlag New York, 2016.\n\n LaTeX ユーザのための BibTeX エントリーは \n\n @Book{,\n author = {Hadley Wickham},\n title = {ggplot2: Elegant Graphics for Data Analysis},\n publisher = {Springer-Verlag New York},\n year = {2016},\n isbn = {978-3-319-24277-4},\n url = {https://ggplot2.tidyverse.org},\n }"
## [3] ""
format(ggplot2_citation, style = "html")
## [1] "<p>Wickham H (2016).\n<em>ggplot2: Elegant Graphics for Data Analysis</em>.\nSpringer-Verlag New York.\nISBN 978-3-319-24277-4, <a href=\"https://ggplot2.tidyverse.org\">https://ggplot2.tidyverse.org</a>. \n</p>"
format(ggplot2_citation, style = "latex")
## [1] "Wickham H (2016).\n\\emph{ggplot2: Elegant Graphics for Data Analysis}.\nSpringer-Verlag New York.\nISBN 978-3-319-24277-4, \\url{https://ggplot2.tidyverse.org}."
format(ggplot2_citation, style = "textVersion")
## [1] "H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016."
format(ggplot2_citation, style = "R")
## [1] "bibentry(bibtype = \"Book\",\n textVersion = \"H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016.\",\n header = \"To cite ggplot2 in publications, please use\",\n author = person(given = \"Hadley\",\n family = \"Wickham\"),\n title = \"ggplot2: Elegant Graphics for Data Analysis\",\n publisher = \"Springer-Verlag New York\",\n year = \"2016\",\n isbn = \"978-3-319-24277-4\",\n url = \"https://ggplot2.tidyverse.org\")"
改行情報が\nで表記される。これはいろいろな用途が考えられるが例えば、ファイルに書き込んだりする時にwriteLines()などを使うときやcat()関数やmessage()関数など\nを改行として解釈する関数に渡すときなどに使える。
また、print()関数では出力スタイルが変わっているだけでオブジェクトそのものはリスト形式のままだが、format()関数だと任意のスタイルの文字列に変えることができる。
x_print <- print(ggplot2_citation, style = "text")
## Wickham H (2016). _ggplot2: Elegant Graphics for Data Analysis_.
## Springer-Verlag New York. ISBN 978-3-319-24277-4,
## <https://ggplot2.tidyverse.org>.
x_print
## To cite ggplot2 in publications, please use
##
## H. Wickham. ggplot2: Elegant Graphics for Data Analysis.
## Springer-Verlag New York, 2016.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Book{,
## author = {Hadley Wickham},
## title = {ggplot2: Elegant Graphics for Data Analysis},
## publisher = {Springer-Verlag New York},
## year = {2016},
## isbn = {978-3-319-24277-4},
## url = {https://ggplot2.tidyverse.org},
## }
x_format <- format(ggplot2_citation, style = "text")
x_format
## [1] "Wickham H (2016). _ggplot2: Elegant Graphics for Data Analysis_.\nSpringer-Verlag New York. ISBN 978-3-319-24277-4,\n<https://ggplot2.tidyverse.org>."
必要な情報だけを取り出す
引用情報のうち一部だけが必要となることがある。citaiton()で作られるオブジェクトはリスト形式なので、必要な中身を$などで取り出すことができる。
citation("ggplot2")$title
## [1] "ggplot2: Elegant Graphics for Data Analysis"
ggplot2_citation <- citation("ggplot2")
ggplot2_citation$title
## [1] "ggplot2: Elegant Graphics for Data Analysis"
複数の引用情報を取り出す
citation()はそのままでは複数のパッケージを指定し、引用情報を取り出すことができない。
citation(c("zipangu", "ggplot2"))
## Error in system.file(package = package, lib.loc = lib.loc): 'package' は長さ 1 でなければなりません
そこで、{purrr}パッケージのmap()関数や、lapply()などの関数を用いることで複数の文献の引用情報をまとめて出力することができる。
purrr::map(c("zipangu", "ggplot2"), citation)
## [[1]]
## 'zipangu' パッケージの引用には以下を用いてください:
##
## Uryu S (2022). _zipangu: Japanese Utility Functions and Data_. R
## package version 0.3.2, <https://CRAN.R-project.org/package=zipangu>.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Manual{,
## title = {zipangu: Japanese Utility Functions and Data},
## author = {Shinya Uryu},
## year = {2022},
## note = {R package version 0.3.2},
## url = {https://CRAN.R-project.org/package=zipangu},
## }
##
## [[2]]
## To cite ggplot2 in publications, please use
##
## H. Wickham. ggplot2: Elegant Graphics for Data Analysis.
## Springer-Verlag New York, 2016.
##
## LaTeX ユーザのための BibTeX エントリーは
##
## @Book{,
## author = {Hadley Wickham},
## title = {ggplot2: Elegant Graphics for Data Analysis},
## publisher = {Springer-Verlag New York},
## year = {2016},
## isbn = {978-3-319-24277-4},
## url = {https://ggplot2.tidyverse.org},
## }
ここで、text形式でlist形式ではなくベクトル形式で引用情報を持っておきたいと持ったら、例えば次のようにするとできる。format()で取り出すと、改行が\nとなるのでこれをスペースで置換しておく。改行情報を持っておきたかったらそのままにしておけばいい。
purrr::map_chr(c("zipangu", "ggplot2"), ~ citation(.x)
|> format(style = "text")
|> gsub(pattern = "\\n", replacement = " ", x = _))
## [1] "Uryu S (2022). _zipangu: Japanese Utility Functions and Data_. R package version 0.3.2, <https://CRAN.R-project.org/package=zipangu>."
## [2] "Wickham H (2016). _ggplot2: Elegant Graphics for Data Analysis_. Springer-Verlag New York. ISBN 978-3-319-24277-4, <https://ggplot2.tidyverse.org>."